
How AI Is Transforming Observability and Incident Management in 2025

Last updated
“Every incident is an opportunity to learn and improve your production health”
Shipping battle-tested code is just half the battle for any software application at scale. It is crucial for organizations to have a robust AI observability and incident management process that can help engineers learn fast through comprehensive logs, metrics, and traces into how systems are behaving in real-time.
In 2025, the rise of AI-powered observability platforms is enabling engineering teams to shift from reactive to predictive workflows as the adoption of AI is moving from experimental to operational phase. Ever since the rise of ChatGPT’s first model in 2023, we’ve seen a huge spike in the number of LLM models in the market.
TRY ZENAI FOR FREE | GET INSTANT SUMMARIES, RCA ASSIST, AND POSTMORTEM REPORTS
According to McKinsey, the use of AI has increased significantly in 2024 as compared to the previous years. Among these, AI for observability and AI in incident management are two of the most adopted engineering applications. 78% of organizations are using AI for at least one business function in 2025, up from 72% in early 2024.
This blog covers key trends in AI incident management software and generative AI use cases in observability. So, let's dive in.
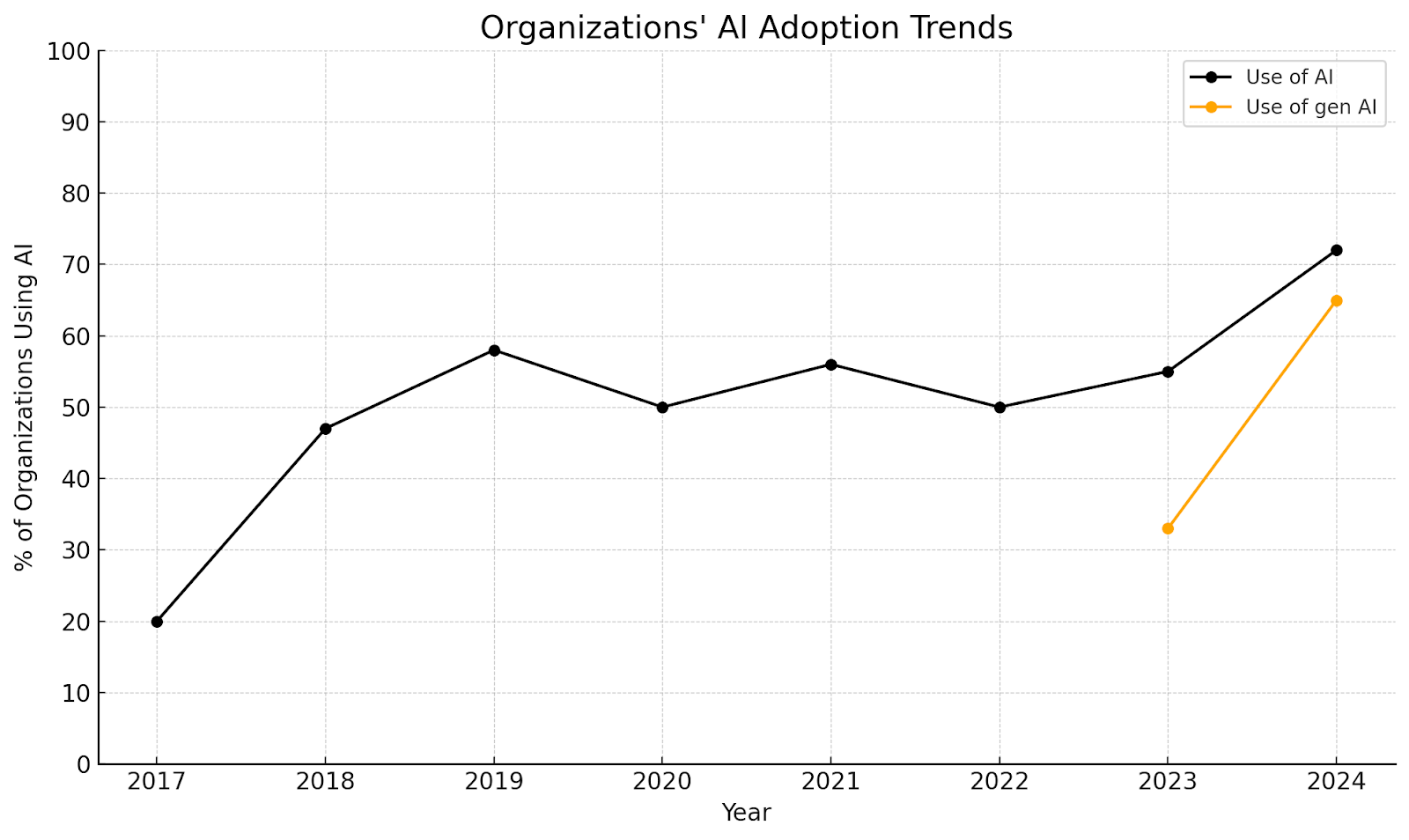
Source: The state of AI: How organizations are rewiring to capture value
General AI Adoption has grown from 20% in 2017 to 72% in 2024, with a plateau from 2019 to 2022.
Generative AI Adoption emerged prominently in 2023 and surged from 33% to 65% in just one year, indicating its rapid integration across industries.
AI-Powered Observability and Incident Response: What's Changing?
Well, an SRE’s job has always involved skimming through a lot of data, logs, and metrics to find context for everything that breaks. Even when nothing is actively going wrong, engineers focus on ways to prevent incidents that could lead to downtime. At Zenduty, we’ve seen our users leverage AI features to simplify tasks like identifying RCA faster, setting up on-call schedules, and even drafting postmortems, saving them hours of manual work.
For enterprises, this means engineers no longer have to stay stuck in loops of repeatable tasks. AI tools help free up their time so they can focus on building infrastructure that is scalable, fast, and reliable. We’re also seeing companies adopt AI observability tools that diagnose system health before anything breaks. According to a recent report from New Relic, there has been a 30% quarter-over-quarter increase in AI adoption in observability. That shows the growing trust companies are placing in tools designed to make engineers' lives easier.
In this blog, we’ll explore some of these AI-driven use cases in incident management and observability, and look ahead at what the future holds for Site Reliability Engineering (SRE). But before we dive in, let’s take a look at some of the common challenges engineering teams face at scale.
Current Challenges in Observability & Incident Management
Most teams think they have a solid incident response setup until it’s tested in real conditions. And that’s when all the hidden cracks show up. The observability stack looks good on paper but falls apart under pressure. Systems are complex. Alerts are noisy. The context lives in people’s heads or in a Slack thread from six months ago. These are the things slowing teams down every day.
The system is observable but unreadable
You can have the best logging, metrics, and tracing in place but still not know what is going on. It’s not about missing data. It’s about having too much of it with no clarity. When everything is monitored, but nothing is obvious, debugging feels like sifting through noise hoping something pops out.
Alerts fire too often or not at all
Most teams tune their alerts based on gut feel or old outages. Over time they stop trusting them. Some alerts go off for low-impact blips. Others never fire at all even when things are clearly wrong. This creates hesitation. Engineers start second-guessing the system. Instead of reacting quickly, they pause to make sure it’s not another false alarm.
RCA is slow and mostly tribal
When an incident hits, everyone scrambles to piece together what happened. You check Grafana. Someone pulls logs. Someone else checks the deployment timeline. It becomes a race to find the first clue. Most RCA work depends on who’s on-call and how well they remember past incidents. If that person is out or new, everything takes longer.
Omkar Kadam, author of 'The DevOps Story,' identifies this as a key area where AI can help bridge knowledge gaps:
Automated RCA' as the top priority where AI can immediately help teams move faster during critical incidents - removing the dependency on tribal knowledge and making root cause analysis consistent regardless of who's on-call.
His vision extends beyond just incident response to using AI for 'Single pane of glass and observability, reducing alert fatigue and AI Assisted Incident Management.'
Documentation and follow-ups don’t scale
After the fire is out, nobody wants to do the cleanup. Writing postmortems, tagging owners, attaching timelines. It all feels like overhead. In many teams, these things are done because they’re required, not because they’re useful. And when they’re rushed, they don’t help anyone. Engineers don’t revisit them. Future incidents don’t benefit from them.
On-call is painful and unpredictable
On-call should be manageable. But in most teams, it drains people. Alerts come in at odd hours. Some are urgent. Most are not. You respond, patch something, and get back to sleep, only to wake up again for another alert that’s barely actionable. It chips away at confidence and slows down learning across the team.
This aligns with what many SREs are looking for. Omkar Kadam highlights 'Automated RCA' and 'Reducing Noisy alerts' as the top areas where AI can make an immediate impact. The goal is moving from alert fatigue to alert confidence.
All these problems make incidents harder to manage. Not because engineers are under-skilled, but because the systems they depend on weren’t built for real-world speed. What’s changing now is that teams have started using AI tools to remove some of this friction..
Let’s break down how that’s already happening and where teams are seeing results in their daily workflows.
Key Use Cases of AI for Observability and Incident Response
In this section, we’ve put together some of the problems that AI is already eliminating for SREs at every stage of the incident timeline. Let’s jump in and see what you can automate today and reduce the toil off of your engineers’, so they can focus on building.
Finding root cause without jumping between five tabs
Most of the time in an incident is spent connecting the dots. You’re checking metrics in one tool, logs in another, and maybe messages in Slack. AI systems can now do that correlation for you. They look at logs, traces, alerts, change events, and past incidents to surface what looks different. It helps narrow down scope without wasting the first thirty minutes looking in the wrong place.
The speed advantage is real. As Karan puts it: 'In the time I login, find and open relevant metrics AI would be reading across them giving it an advantage for anomaly detection and resolution.' This time compression is crucial during high-stakes incidents where every minute of downtime has significant business impact.
Postmortems that don’t start from a blank doc
No one enjoys writing postmortems. Especially when the details are scattered across alert logs, incident timelines, and chat transcripts. AI can now pull all of that together. It builds a timeline, pulls out relevant events, and gives you a draft you can review. You still edit. You still add context. But you don’t have to start from scratch. That small shift saves hours.
Alerts that learn what to ignore
A lot of alerting is trial and error. One noisy rule affects the entire team. AI can help by learning what normal looks like. It understands recurring patterns and suppresses known noise. If something spikes every Monday morning but recovers in five minutes, it doesn’t wake you up. That one change improves trust in alerts across the team.
Escalations that don’t break rotation
Figuring out who to escalate to should not be a blocking step. AI helps by looking at who’s resolved similar issues before. It learns from incident history, not just shift calendars. This reduces the time it takes to bring in the right person. It also helps avoid fatigue for the same set of engineers who always get looped in first.
Spotting early signals before users do
There are always weak signals before an outage. Slow DB queries. Retry loops. Gradual error rate creep. Engineers usually spot these after the fact, buried inside logs or a forgotten dashboard. AI can surface these changes while they’re still small. But here's the key insight from teams running at massive scale:
Karan Kaul from JioHotstar, who builds high-scale video systems at JioHotstar, puts it simply:
To build truly intelligent systems, it's essential to train your AI models on QoE metrics captured from user devices, rather than relying solely on conventional QoS indicators. This ensures your models learn from the nuanced conditions that precede and predict real-world experience degradation.
This user-centric approach to AI-powered anomaly detection ensures that performance issues are caught from the end-user perspective, not just server-side monitoring.
The best thing is these aren’t just ideas. Teams are already using these in production. The AI is not perfect, but it’s useful. It removes the repetitive parts that slow engineers down. And once that friction is gone, teams can actually focus on what matters.
What’s still missing for most teams is a way to adopt these tools without adding more complexity. In the next section, we’ll go into how to build for AI-first incident management without creating more process than progress.
How to Build for AI-First Incident Management and Observability
Implementing a modern AI-enabled incident management system starts by integrating with your existing tooling stack. If AI is going to fit into your incident workflow, it has to be useful in motion. That means no extra dashboards, no side workflows, and definitely no new tickets to manage AI outputs. The right setup makes AI feel like part of the team, and not another system to manage. That’s our philosophy at Zenduty too, adding AI as your team’s new SRE that doesn’t run on coffee.
Start where the friction is highest
The best way to bring in AI is to aim at what’s already slowing your team down. Look at how much time is spent on RCA, writing postmortems, triaging alerts, or doing escalations. These are the spots where AI works best because the work is mostly mechanical and always time sensitive.
Keep humans in the loop for every decision
AI can suggest a cause, draft a summary, or recommend an action. But it should never act without a human saying yes. You still want your engineer to validate before muting alerts or declaring resolution.
Integrate with what the team already uses
Engineers don’t want to switch tools during an incident. AI needs to plug into the systems where work already happens. That means inside your alerting platform, inside Slack or Teams, inside your AI observability stack. The more native the experience feels, the more likely it is that your team will actually use it.
Make feedback loops part of the workflow
AI gets better when it learns from how your team responds. If it makes a suggestion that’s wrong, log that. If it helps resolve an incident faster, track it. Build feedback into the post-incident review so your system improves over time.
Treat adoption like feature rollout, not a process change
You don’t need a new playbook to use AI. You just need a small, clear rollout plan. Pick one use case. Introduce it in one team. Share results. Then expand.
The teams who get this right are the ones who treat AI as a tool to remove blockers, not to reinvent processes. They start with what’s broken, fix it with AI where it helps, and keep the rest simple.
Are you ready to adopt AI in Incident Management?
If you've been thinking about removing friction from incident workflows, Zenduty's new AI features are built to do exactly that. We've added smart tooling that helps teams:
- Find RCA faster with less digging
- Summarize incidents in real time
- Auto-draft postmortems that actually save time
- Create fair, balanced on-call schedules
Frequently Asked Questions on AI in Incident Management and Observability
AI incident management refers to the use of artificial intelligence to automate and streamline tasks like detecting issues, correlating events, escalating incidents, and generating post-incident reports. It's gaining traction in 2025 as engineering teams seek to reduce manual toil and improve response times.
AI enhances observability by recognizing patterns across logs, metrics, and traces, allowing for earlier detection of issues and less noise. Instead of relying on static thresholds, AI systems learn from data trends to detect anomalies before they cause outages.
AI helps with automatic RCA, suppressing false alerts, escalating to the right engineers, and generating draft postmortems. These features reduce mean time to resolution (MTTR) and make on-call less stressful for SREs and engineers.
Traditional observability relies on dashboards and alerts manually configured by engineers. AI-powered observability adds intelligence by automating insights, identifying hidden patterns, and enabling predictive diagnostics — often before users report an issue.
Start by identifying high-friction tasks — like RCA, alert triage, or writing postmortems — and experiment with automation in those areas. Small pilot integrations can show value without requiring full-stack overhauls.
Yes, generative AI can now aggregate signals from logs, alerts, and chat transcripts to create initial postmortem drafts. These drafts often save engineers hours by providing a structured summary that can be reviewed and refined.
Some tools like Zenduty, Datadog, and Blameless offer AI modules that help automate root cause analysis, reduce noise, and improve alert routing. These platforms vary in features, but all aim to reduce response times and increase reliability.
Absolutely. Lightweight AI observability tools can help small teams gain insights without adding more dashboards or manual analysis. Even a basic integration can provide significant value for uptime and performance tracking.
Generative AI is helping teams synthesize information faster — creating incident timelines, summarizing anomalies, and even suggesting next actions. This removes a major cognitive load from on-call engineers.
Key trends include increased adoption of agentic AI, predictive observability platforms, AI-led RCA, and tighter integrations with collaboration tools. As the ecosystem matures, more teams are shifting from reactive to proactive operations.

Rohan Taneja
Writing words that make tech less confusing.
