
Balancing Proactive Work and Firefighting in Site Reliability Engineering

Last updated
As an SRE, you constantly juggle proactive tasks to improve reliability and scalability with reactive firefighting when issues arise—often leaving little time to address the root causes.
This is not unlike the firefighters of Ancient Rome, the Vigiles, who were tasked with not only responding to fires but also preventing them. Established in 6 AD under Emperor Augustus, the Vigiles patrolled the streets of Rome, looking for potential fire hazards.

Similarly, SREs today often find themselves constantly reacting to system outages or performance issues, but with the right tools, they can transition to a more proactive role.
The Challenge of Constant Firefighting
Just as the Vigiles needed to break the cycle of merely reacting to fires, SREs face a similar challenge. When too much time is spent on reactive firefighting, it leaves little room for addressing the root cause of incidents. According to a 2024 SRE report, 47% of teams struggle with incident learning and fixing recurring issues, leading to increased technical debt. Without addressing the underlying causes, future incidents become more likely, and long-term planning, such as scalability, gets pushed aside.

Strategies for Balancing Proactive and Reactive Work
To effectively balance proactive work and reactive firefighting, you need a thoughtful strategy. Here are some ways that can help SREs manage both sides of the equation:
Error Budgets
Error budgets can be a game-changer when it comes to balancing your time. Essentially, an error budget sets a limit on how much downtime or failure is acceptable, typically defined by your Service Level Objectives (SLOs). It gives your team the flexibility to innovate and experiment without worrying too much about perfection.
When you're within your error budget, it’s a sign that you can focus on proactive work. However, once you exceed that budget, it's time to prioritize fixing issues and stabilizing the system.
Automating the Firefighting
Firefighting doesn’t always have to be chaotic or manual. In fact, automation can drastically reduce the time you spend on reactive work, freeing you up for more strategic, forward-looking tasks.
- Automated Detection: Use tools like Prometheus or Datadog to automatically detect anomalies before they escalate into full-blown incidents. Catching issues early can prevent a lot of firefighting down the road.
- Runbook Automation: If you’re dealing with the same issues over and over, automating the response with tools like RunDeck or Ansible can save you a ton of time. These tools allow you to define automated responses for recurring incidents.
- Self-Healing Systems: Setting up self-healing systems in Kubernetes is a great way to reduce manual intervention. Tools like Kubernetes can automatically restart unhealthy pods, and runbooks can handle recurring incidents, reducing manual intervention by up to 40%.
Incident Triage and Categorization
Not every incident is urgent. By categorizing issues based on their severity, you can ensure that your time is spent on the highest-priority problems first.
- P0 (Critical): These are major outages that need immediate attention.
- P1 (High): Significant, but not system-wide issues. They still require fast responses but aren’t quite as urgent as P0 incidents.
- P2 (Medium): Services that are degrading but don’t need to be addressed right away.
- P3 (Low): Minor bugs that can wait until routine maintenance or the next available time.
This kind of categorization helps you avoid spending time on low-priority issues when there are more critical fires to put out.
Structured On-Call Rotations
On-call rotations are a necessary part of SRE work, but if they aren’t structured properly, they can lead to burnout. A well-managed system ensures that everyone shares the burden of incident management, and no one is stuck firefighting all the time.
- Rotate Responsibilities: Make sure on-call shifts are rotated equally across the team, so no one person bears the brunt of firefighting.
- Post-Incident Downtime: After handling a major incident, it's essential to give your engineers time to recover. Let them take a break before jumping back into proactive work.
- Reduce Alert Fatigue: Too many alerts can be overwhelming. Fine-tune your alerting system so that only the most critical incidents trigger notifications. This reduces unnecessary interruptions and ensures that engineers can focus on proactive tasks without constant distractions.

Gaining Buy-In for Proactive Work
Balancing proactive work with firefighting isn’t something you can do on your own. It requires support from the entire organization. Often, proactive tasks like improving automation or scaling systems are seen as “nice-to-haves” by leadership, but you need to demonstrate how these improvements will actually reduce the need for firefighting over time.

- Use Data: Presenting incident data to leadership can help show how recurring problems could be solved with proactive work. It’s easier to justify proactive improvements when you can quantify the long-term savings in time and resources.
- Showcase Success: After implementing automation or other improvements, be sure to share the results. Reduced incident volumes and faster response times are powerful ways to show the impact of proactive work.

Continuous Improvement with Post-Incident Reviews
Every incident is a chance to improve. Post-incident reviews (or post-mortems) help you learn from each incident and take steps to prevent it from happening again.
- Blameless Post-Mortems: Keep the focus on learning, not blaming. The goal is to improve systems, not point fingers.
- Actionable Follow-Ups: Every review should result in specific, actionable steps to prevent similar incidents in the future.
- Automate Fixes: Where possible, automate the solutions identified during post-mortem reviews. This way, you reduce the chance of the same issue recurring in the future.
McDonald's Ice Cream Machine Fail–The McBroken Incident
The same principle applies to businesses outside of tech as well. Take McDonald’s ice cream machines, for example. In 2020, these machines became the center of a public relations issue when they frequently went out of service, much to the frustration of customers.
Rashiq Zahid, a frustrated customer, created McBroken.com to track which machines were operational. The data showed that 15% of McDonald's ice cream machines were unavailable at any given time.
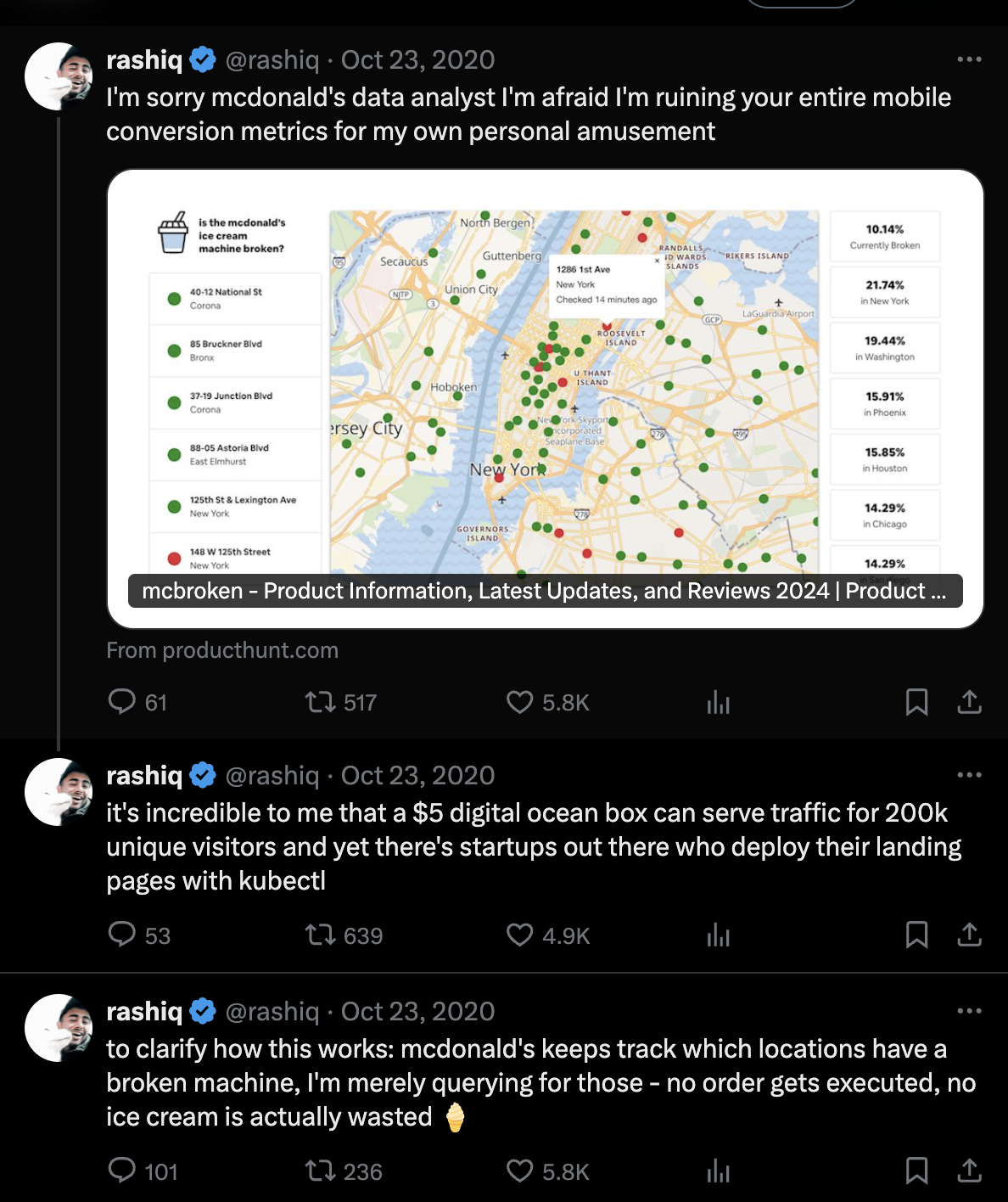
“I love poking around in different apps and just looking at the security features and the internal APIs,” Zahid said. “I am pretty familiar with how to reverse-engineer apps. I was like ‘Okay, this should be pretty easy.’”
Seeing this, Wendy’s jumped in and partnered with McBroken to offer $1 Frostys at locations where McDonald's machines were down, turning McDonald's ongoing issue into a marketing win for Wendy’s.
When you don’t fix underlying problems, small issues can become public frustrations. In McDonald’s case, this led to a damaged reputation and competitors swooping in to capitalize on their failure. Not addressing root causes can result in missed opportunities and competitors gaining the upper hand.
Conclusion
Balancing proactive work with firefighting is a challenge, but it’s crucial for maintaining the health and reliability of your systems. By using strategies like error budgets, automation, and proper incident triage, you can make firefighting a rare event, rather than the norm.
Ready to stop firefighting and start building proactive solutions? Try Zenduty for free and experience how automated incident management can streamline your workflow.

✅ FREE 14 DAY TRIAL | ✅ NO CREDIT CARD REQUIRED | ✅ PRIORITY SUPPORT

Rohan Taneja
Writing words that make tech less confusing.
