
20 Most used incident management tools in 2025

Last updated
Every engineering leader knows downtime is expensive. Gartner estimates that even moderate outages cost thousands of dollars per minute, and data shows that structured postmortems can cut repeat incidents by 24%. In 2025, with cloud-native complexity, microservices sprawl, and remote-first teams, incident management software makes for all the difference between chaos and reliability.
The challenge most teams today face is too many alerts. According to reports, that get thousands of alerts per week, but only ~3% require urgent action. Now, that’s a very small percentage and the rest of the 97% of alerts are just noise. Noise creates fatigue, slows MTTR, and burns out your engineers which in turn add unfair on-call rotations or missing automation, and in the end, response breaks down.
That’s why modern SRE and DevOps teams don’t just want a tool that just alerts. They want an end to end incident management software that can filter signals, assign roles, automate response, and ensure learnings stick. Tools that combine on-call, AI, and retrospectives are now table stakes. A 2024 survey shows 65% of organizations are already using automation in incident management, with another 20% planning to adopt.
In this blog, we’ll be exploring top incident management tools in 2025 that help enterprises stay ahead of incidents with proactive prevention than firefighting incidents without any track. Here’s the shortlist of platforms that reliability teams actually trust in production. Zenduty leads the pack as the AI-first incident management solution built to reduce noise, improve MTTR, and keep on-call humane.
List of top 20 incident management software in 2025
| # | Tool | Best For | Starting Price |
|---|---|---|---|
| 1 | Zenduty | AI-driven incident management for SRE/DevOps | Free, then $5/user/mo |
| 2 | PagerDuty | Legacy enterprise IT operations | $29/user/mo |
| 3 | OpsGenie | Jira/Atlassian shops (EOL soon) | $9/user/mo |
| 4 | Rootly | Slack-native incident automation | Contact sales |
| 5 | incident.io | Chat-first, L1 support & incident comms | From ~$12/user/mo |
| 6 | FireHydrant | Runbooks & post-incident reviews | $10/user/mo |
| 7 | Squadcast | Affordable SRE/DevOps platform | $9/user/mo |
| 8 | Grafana OnCall | On-call inside Grafana Cloud | Free, paid tiers |
| 9 | Splunk On-Call (VictorOps) | Ops-heavy Splunk observability users | Contact sales |
| 10 | BigPanda | Large-scale alert correlation (AIOps) | Enterprise pricing |
| 11 | xMatters | Workflow automation across ITSM/DevOps | Contact sales |
| 12 | Better Stack | Monitoring + incidents + status pages | Free, then $24/mo |
| 13 | Moogsoft | AIOps noise reduction & incident grouping | Contact sales |
| 14 | OnPage | Healthcare & secure incident paging | $12/user/mo |
| 15 | PagerTree | Simple alert routing for small teams | From $10/mo |
| 16 | Spike.sh | Budget-friendly incident response | From $5/mo |
| 17 | iLert | EU-friendly on-call & status pages | From €8/user/mo |
| 18 | ManageEngine ServiceDesk Plus | ITSM suite with incident/change/CMDB | Contact sales |
| 19 | Freshservice | Cloud ITSM for IT helpdesks | From $19/user/mo |
| 20 | Jira Service Management | Atlassian-native ITSM & incidents | From $20/user/mo |
Why do teams need incident management software at all?
If you land on this blog, we’re sure you’re facing something like this:
Last time something broke at 2 AM and alerts were flying from five different tools, Slack was blowing up, nobody knew who was actually owning the incident, and the customer success team was already pinging for updates. By the time you found the right logs, half the team was awake and productivity the next day was gone.
That’s the gap incident management software fills. It gives you:
- A single place to route and prioritize alerts so you’re not chasing noise.
- Clear on-call ownership so everyone knows who’s responsible.
- Built-in comms, status pages, and stakeholder updates so engineers aren’t doubling as PR.
- Post-incident reports that actually get read and acted on, instead of rotting in Confluence.
At scale, you can’t duct tape this together with Slack and AlertManager alone. Modern teams want faster MTTR, fewer false alarms, and a process that doesn’t burn people out. Incident management software is how you get there or as we like to day, an end-to-end incident management software will help you foster a culture of reliability within your organization.
Top 20 best incident management software in 2025
Here’s the rundown of the top 20 incident management software tools that we're seeing SREs, DevOps, and IT ops teams actually rely on in 2025.
Whether you're looking to reduce downtime, streamline on-call rotations, improve SLA/SLO compliance, or just filter out alert noise; this list will help you quickly scan, compare, and decide which incident management solution deserves a spot in your toolbox.
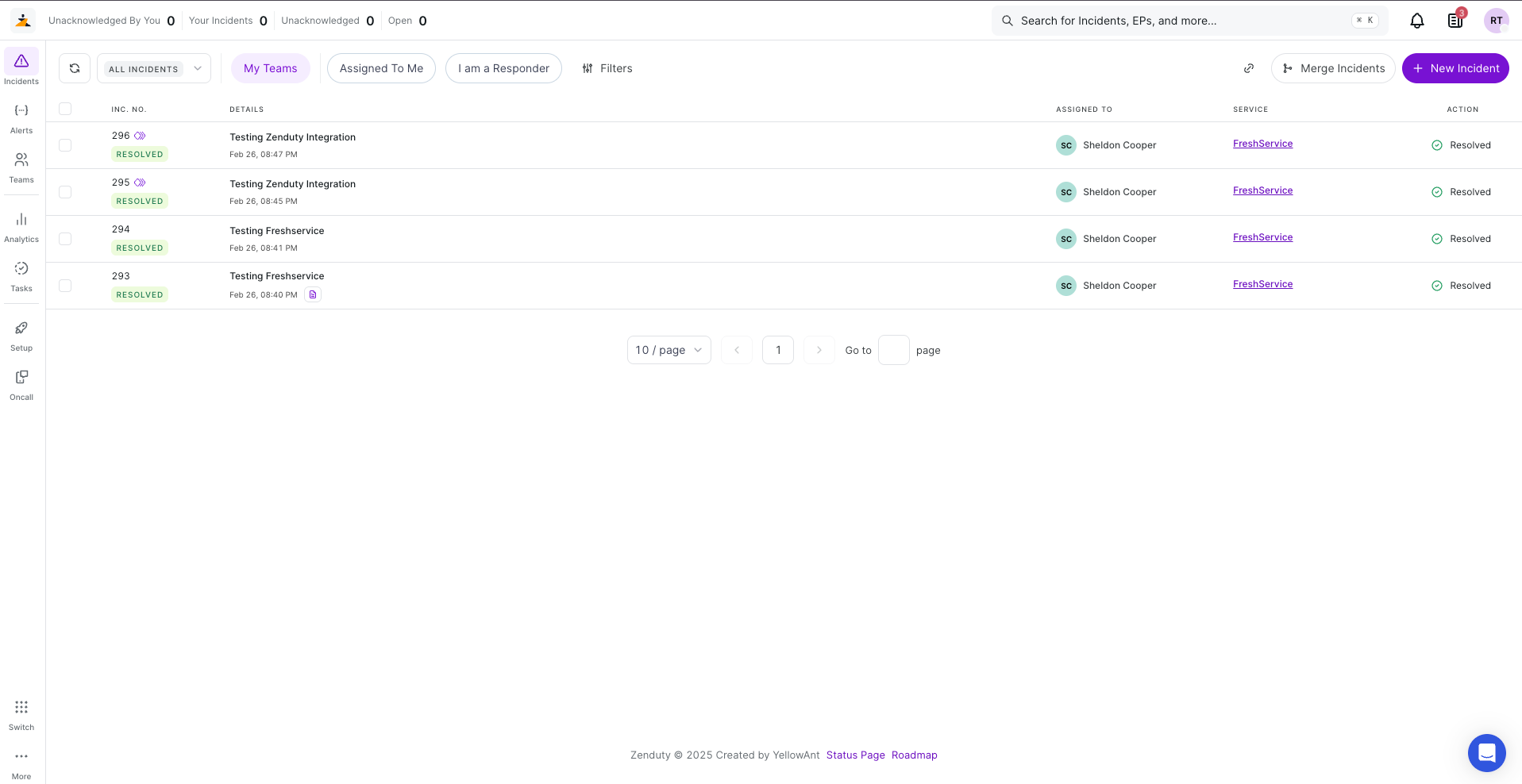
1. Zenduty | AI-native incident management tool for enterprise
- 💰 Starting price: Free plan available, paid plans from $5/user/month
- 🤖 AI-powered incident management software: Yes (ZenAI for context, RCA, and postmortems)
- 💻 Read Zenduty reviews for more information

Zenduty was built for engineering teams who are tired of juggling noisy alerts, messy handoffs, and endless firefights.
Where legacy tools focus on just alerting your engineers, Zenduty integrates directly into the detect → orchestrate → resolve → improve lifecycle of incidents.

It fits into the cycle and helps your teams even learn after an incident is resolved by generating AI-postmortems that help reduce repeated incidents.
Key features of Zenduty
Here’s what sets Zenduty apart:
- Noise Reduction That Works: Intelligent suppression and context-rich alerting cut through the flood of signals, so engineers see only what matters.
- AI-Powered RCA: ZenAI surfaces root causes, builds incident timelines, and even generates auto-postmortems, saving hours of manual effort.
- Automate Incident Handing with Workflows: With Workflows, you can now set up automations like auto-resolving low-priority incidents after a set time, triggering a major incident flow that alerts leadership and escalates if an incident is critical, or kicking off a predefined runbook via webhook the moment a P1 hits.
- Human-Friendly On-Call: Customizable schedules, fair escalations, and seamless follow-the-sun coverage keep on-call rotations humane.
- ChatOps at the Core: Incidents spin up instantly in Slack or Teams, with role-based assignments and playbooks triggered in real time.
- Actionable Postmortems: Auto-generated reports feed action items straight into Jira or GitHub, ensuring learnings don’t rot in Confluence.
- Migration Made Simple: Zenduty’s migration script makes it painless to move off PagerDuty, OpsGenie, or other tools in minutes.
- Enterprise-Ready: SOC 2 Type II, ISO 27001, and GDPR compliance ensure Zenduty meets strict enterprise security needs.
- ✓Transparent pricing (free tier, paid plans start at $5/user/month)
- ✓AI-driven context saves hours during incidents
- ✓Strong ecosystem of integrations with monitoring, observability, and ITSM tools
- ✓Easy migration path from legacy incident management systems
- ×Doesn’t overload teams with ITIL-heavy processes. Zenduty is built for speed, not red tape
- ×Focused on SREs, DevOps, and engineering use cases, but also works great for traditional IT helpdesks or customer support, which is why it works so well for modern production teams
What’s New With Zenduty?
- ✓ZenAI auto-generates incident summaries and postmortems
- ✓AI SRE helps find RCA and compelx alert routing prevent burnout and alert fatigue
- ✓One-click migration scripts make switching from legacy tools frictionless
Our Testing Notes
During testing, Zenduty stood out for its ChatOps integration. Just spun up a Slack incident channel, and ZenAI instantly summarized the payload, flagged likely root causes, and created a timeline. Escalations were smooth, and swapping on-call shifts took just two clicks. Compared to PagerDuty’s heavier interface, Zenduty felt lightweight and more intuitive for SRE workflows.
How Much Does Zenduty Cost?
Bottom Line: Should You Use Zenduty?
If you’re evaluating incident management tools in 2025, Zenduty should be at the top of your list. It’s the best incident management software for SRE and DevOps teams that want AI-driven context, fewer false alarms, and faster MTTR, all without legacy complexity or bloated pricing.
Zenduty is suitable for:
- ✓Teams scaling reliability without burning budget
- ✓SREs and DevOps engineers tired of noisy alerts
- ✓Organizations adopting AI-driven incident response software
Zenduty isn’t suitable for:
- ×IT teams looking for complex, time-consuming and manial ITIL workflows like ServiceNow
- ×Organizations that only want a simple pager without full incident management
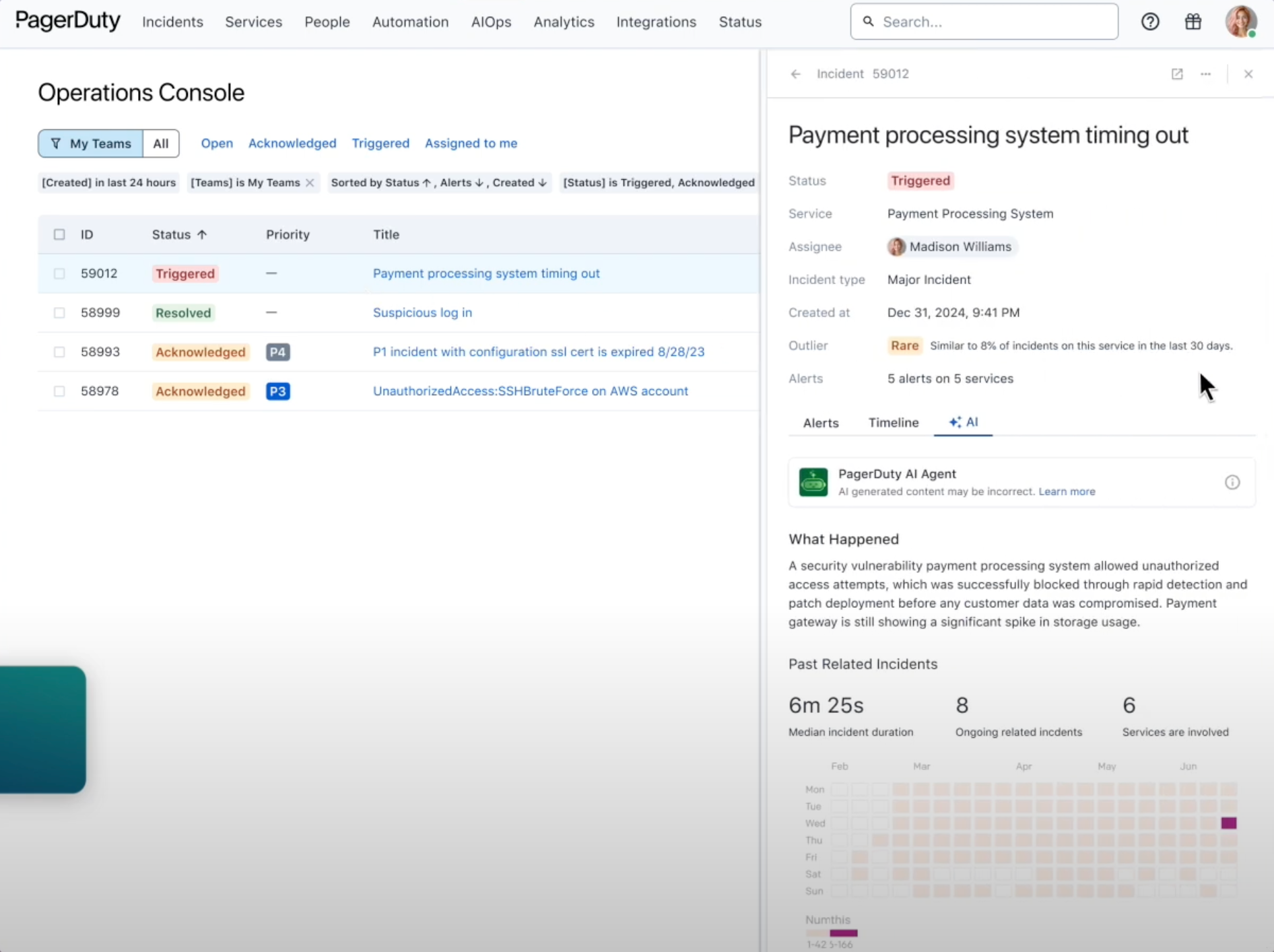
#2. PagerDuty
- 💰 Starting price: Team plan from a whooping $29/user/month + add-ons
- 🤖 AI features: Yes (AIOps, event intelligence, automation
- 💻 Read PagerDuty review for more information

PagerDuty has long been the most recognized name in incident management software, but in 2025 it feels more like a legacy enterprise platform than a modern incident management solution. It delivers a deep feature set including on-call scheduling, escalations, AIOps, and ITIL-style workflows, but the trade-off is complexity, steep pricing, and a slower user experience compared to newer incident management tools.
Key Features
- Incident response software with AIOps and event intelligence
- On-call scheduling and complex escalation policies
- Integrations with monitoring and observability systems
- Built-in runbook automation and workflows
- Role-based permissions and enterprise compliance
✔️ Pros
- ✓Mature platform with years of enterprise adoption
- ✓Wide ecosystem of integrations across ITSM, monitoring, and observability
- ✓Rich automation features for large operations teams
- ✓Strong security and compliance posture
❌ Cons
- ×High pricing, starting at $29/user/month, scales aggressively as teams grow
- ×Complex setup and configuration — steep learning curve for new users
- ×Legacy feel: heavy UI and workflows that slow down smaller or agile teams
- ×Best suited for traditional IT environments, not modern cloud-native SRE/DevOps
What’s New With PagerDuty?
- ✓Incremental updates to AIOps features
- ✓Deeper alignment with ITIL and enterprise ITSM processes
- ✓Expanded automation features, but still geared toward large enterprises
Our Testing Notes
In testing, PagerDuty felt powerful but dated. The scheduler and escalation policies are undeniably robust, but configuring them took time and expertise. The interface is cluttered, and navigating through menus slowed down workflows. Pricing also stands out — for a 50-person team, PagerDuty quickly becomes a significant line item. It’s reliable but feels like a tool designed for 2015 IT operations, not 2025 SRE workflows.
How Much Does PagerDuty Cost?
Bottom Line: Should You Use PagerDuty?
PagerDuty remains one of the most recognized incident management tools, but it comes with the baggage of being a complex, price-heavy, and legacy-oriented platform. It still works well for large IT departments entrenched in ITIL processes, but for modern engineering teams, its cost and complexity can outweigh the benefits.
PagerDuty is suitable for:
- ✓Large enterprises with traditional IT operations
- ✓Teams needing compliance-heavy workflows and strict role management
- ✓Organizations already invested in ITIL and legacy ITSM tooling
PagerDuty isn’t suitable for:
- ×SRE/DevOps teams that want fast, lightweight incident management software
- ×Small and mid-sized companies sensitive to per-user pricing
- ×Modern cloud-native teams looking for speed and simplicity
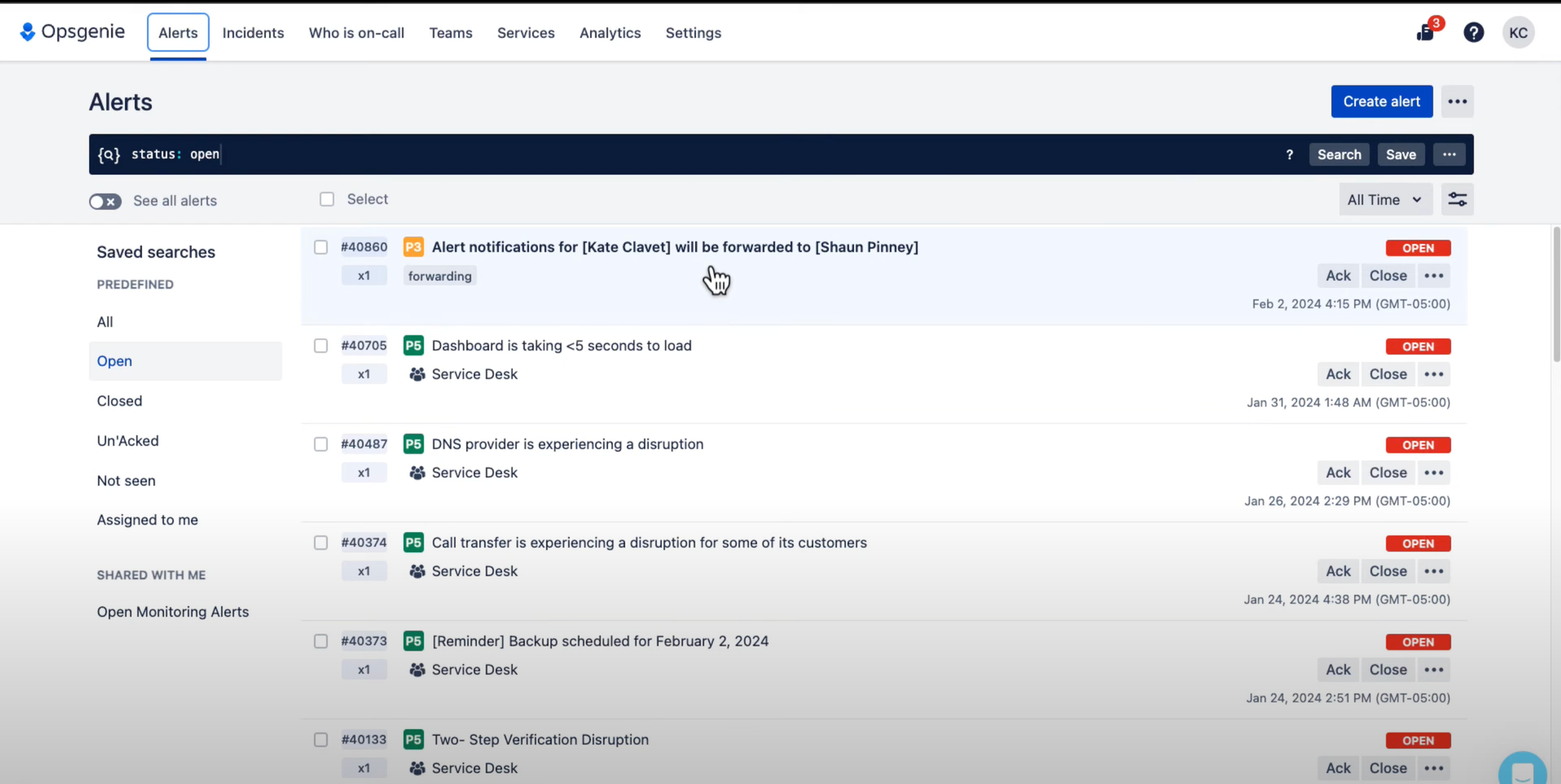
#3. Atlassian OpsGenie
- 💰 Starting price: $9/user/month (Essentials plan)
- 🤖 AI features: Limited (basic automation, not modern AI incident management software)
- 💻 Read OpsGenie review for more information
OpsGenie has been Atlassian’s incident management solution for years, offering alert routing, escalation policies, and integrations with Jira. But in 2025, OpsGenie is approaching end of life (EOL), with Atlassian directing customers toward Jira Service Management instead. This makes OpsGenie a risky bet for teams looking for long-term reliability. While it still functions, investing in a tool that is being phased out is rarely the right move for modern SRE or DevOps teams.
Key Features
- On-call scheduling and escalation workflows
- Native Jira and Confluence integration
- Status page and stakeholder notifications
- 200+ integrations with monitoring and ITSM tools
- Multi-channel notifications: SMS, phone, mobile app, Slack, Teams

✔️ Pros
- ✓Affordable starting price compared to legacy enterprise tools
- ✓Native Jira and Confluence ecosystem integrations
- ✓Simple on-call scheduling and escalation management
❌ Cons
- ×Reaching end of life — not future-proof for 2025 and beyond
- ×Minimal modern AI/automation for incident response
- ×Limited roadmap as Atlassian prioritizes Jira Service Management
What’s New With OpsGenie?
Mostly maintenance updates. Atlassian guidance emphasizes migration paths to Jira Service Management for incident management system software requirements.
Our Testing Notes
Set up was straightforward for alert routing and schedules, but the product feels frozen. For teams planning multi-year reliability investments, moving to a supported incident management platform aligned with cloud-native SRE workflows is the safer path.
Given its end-of-life trajectory and limited AI features, OpsGenie is not a long-term choice for incident management software in 2025. Teams on Atlassian should consider consolidating into Jira Service Management or migrating to a modern incident response platform.
OpsGenie is suitable for:
- ✓Short-term Jira-centric teams needing basic alerting
- ✓Organizations already planning migration to JSM
OpsGenie isn’t suitable for:
- ×SRE/DevOps teams needing modern AI-assisted incident response
- ×Enterprises seeking a future-proof incident management solution
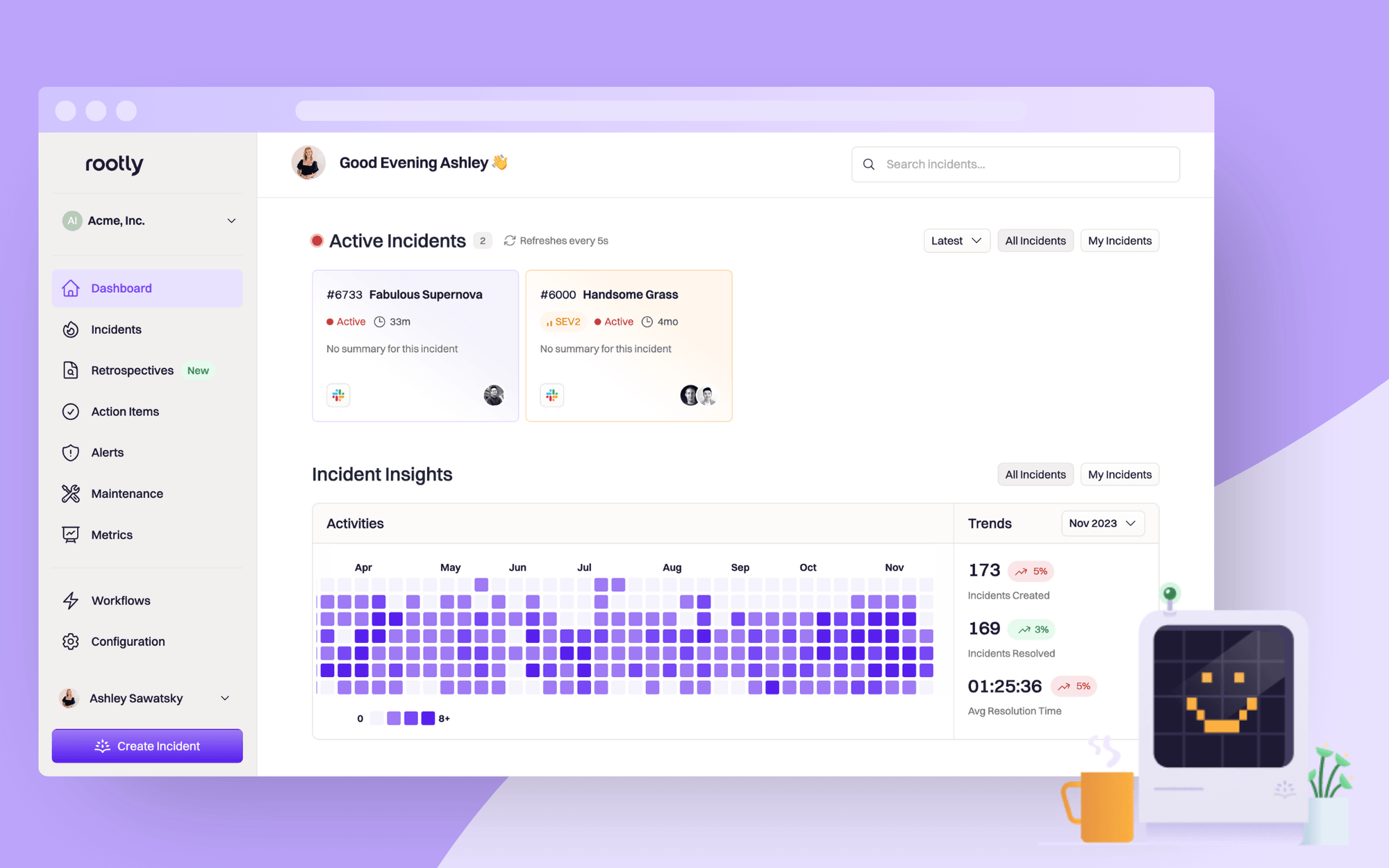
#4. Rootly
- 💰 Starting price: $25/user/month (Business plan)
- 🤖 AI features: Contextual incident summaries and automation inside Slack
- 💻 Rootly reviews on G2
Rootly is an incident management tool built directly into Slack. It helps engineering and SRE teams trigger incidents, assign responders, and generate timelines without ever leaving chat. As a Slack-native solution, Rootly works well for teams that want their incident response software embedded where conversations already happen. But outside Slack, its usefulness is limited compared to broader incident management systems software.
Key Features
- Incident declaration, escalation, and role assignments in Slack
- Automated timelines and postmortems
- Integrations with Jira, GitHub, and cloud monitoring tools
- AI-generated incident updates and summaries
- Prebuilt workflows for common incident response playbooks
✔️ Pros
- ✓Seamless Slack integration — incidents managed directly in chat
- ✓Easy adoption for teams already living in Slack
- ✓Automation for timelines, postmortems, and task tracking
- ✓Growing library of prebuilt workflows
❌ Cons
- ×Slack dependency — limited value for Teams or email-driven orgs
- ×Pricing starts higher than many competitors
- ×Niche outside Slack, lacks broad observability and ITSM depth
- ×Better fit for smaller, fast-moving teams than enterprise IT
What’s New With Rootly?
- ✓AI-powered summaries for incident channels
- ✓New integrations with Atlassian tools like Jira Service Management
- ✓Templates for compliance-driven postmortems
Our Testing Notes
In testing, Rootly was intuitive inside Slack. Declaring incidents was as simple as a slash command, and AI summaries sped up postmortems. But the platform feels confined — teams not fully Slack-centric may struggle. Pricing also scales quickly as user counts grow.
Rootly works best for Slack-native engineering teams that want incident management software embedded in chat. For broader ITSM or observability needs, other tools may be more suitable in 2025.
Rootly is suitable for:
- ✓Teams running incidents entirely in Slack
- ✓Fast-moving orgs wanting automation without heavy process
- ✓Companies prioritizing chat-based collaboration
Rootly isn’t suitable for:
- ×Enterprises needing wide ITSM and compliance support
- ×Teams using Microsoft Teams or email-driven workflows
- ×Organizations sensitive to per-user pricing at scale
#5. incident.io
- 💰 Starting price: Free tier, paid from $19/user/month
- 🤖 AI features: Basic summaries and automation in Slack
- 💻 Best for: Teams handling frontline/L1 incidents inside Slack
incident.io is a Slack-native incident management tool that focuses on lightweight workflows, on-call, and status pages. It shines for L1 support teams and customer-facing incidents where speed of communication matters more than deep integrations or ITSM rigor. While it’s polished and fast in Slack, it lacks the depth expected by SRE and IT operations teams who need advanced automation, reliability analytics, or enterprise-grade ITSM alignment.
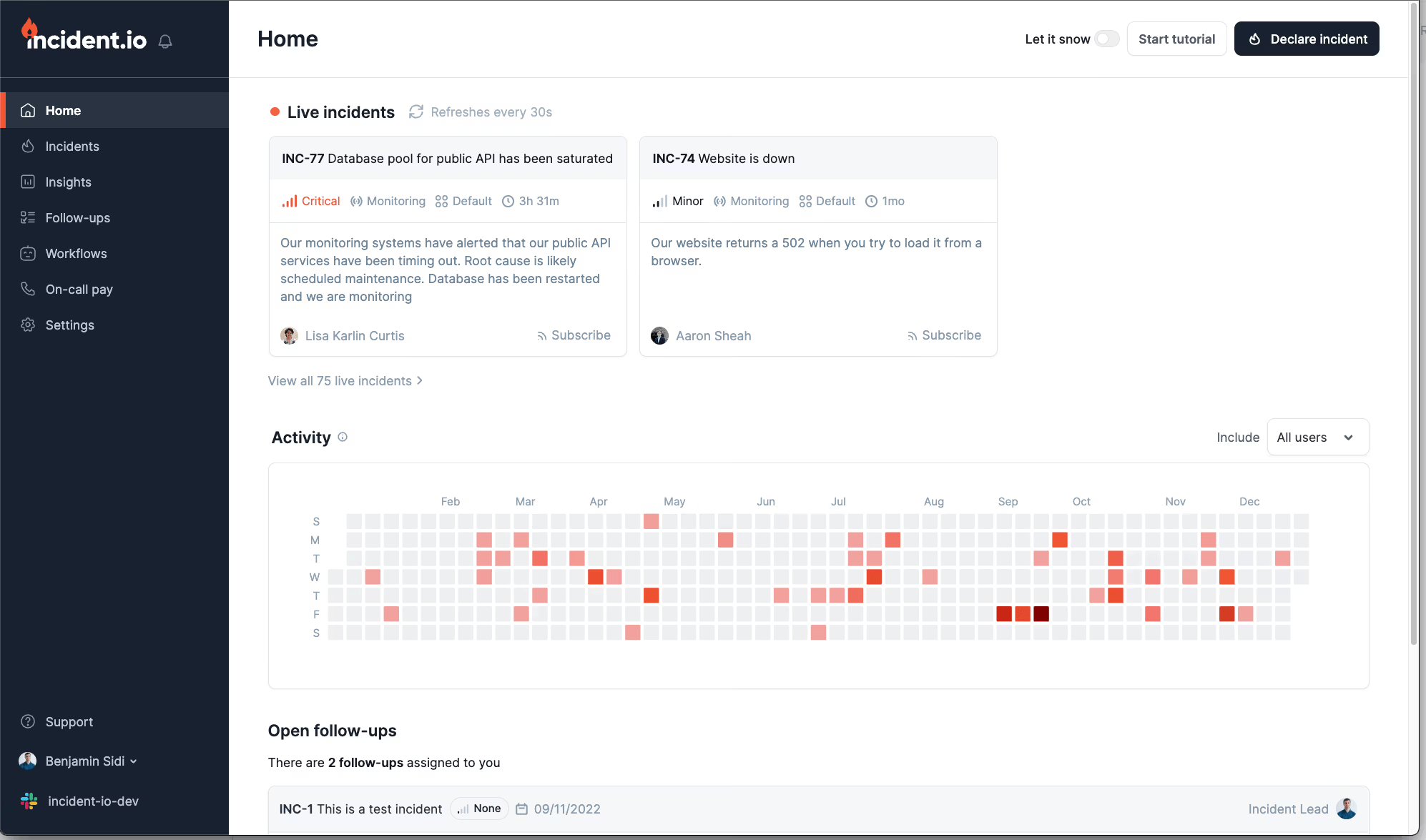
Key Features
- Slack-based incident declaration, escalation, and timelines
- On-call add-on with schedules, escalations, and routing
- Postmortems, status pages, and stakeholder updates
- Mobile app for acknowledgements and quick response
- AI summaries of Slack channels and incident updates
✔️ Pros
- ✓Smooth Slack-native experience for incident declaration and updates
- ✓On-call add-on integrates with alert sources and escalation paths
- ✓Good for customer-facing/L1 support incidents with fast comms
- ✓Includes postmortems, status pages, and basic AI summaries
❌ Cons
- ×Most value assumes Slack — Microsoft Teams only at Enterprise tier
- ×Per-user pricing for on-call adds up quickly at scale
- ×Geared more toward L1 support use cases than SRE/ITSM operations
- ×Lacks depth in automation, observability, and enterprise ITSM features
What’s New With incident.io?
- ✓Expanded on-call features with routing, scheduling, and escalation policies
- ✓Improved AI channel summaries for Slack incidents
- ✓Status page and workflow updates for better L1 support communication
Our Testing Notes
incident.io was intuitive in Slack declaring incidents and assigning responders took seconds. The downside is that it felt more tailored to customer-facing or L1 tickets than complex SRE scenarios. Pricing was simple to understand, but on-call costs ramp up fast for larger teams. For ITSM or reliability-heavy orgs, it lacks the breadth of integrations and governance features.
incident.io fits best for Slack-native organizations handling L1 support incidents. It offers solid basics response, on-call, status pages — but lacks the depth SREs and IT teams expect from enterprise incident management software. For frontline comms it works, but as a long-term reliability platform, it leaves gaps.
incident.io is suitable for:
- ✓Teams resolving customer-facing or L1 incidents quickly in Slack
- ✓Small orgs that want incident response and status pages bundled
- ✓Startups already all-in on Slack workflows
incident.io isn’t suitable for:
- ×Enterprises needing ITSM depth or advanced SRE automation
- ×Teams on Microsoft Teams without Enterprise budgets
- ×Organizations scaling beyond basic L1 support processes
More incident management software to consider
Quick picks with one-line guidance. These complement the Top 5 above and are used by SRE, DevOps, and IT ops teams.
#6. FireHydrantpost-incident
#7. SquadcastSRE/DevOps
#8. Grafana OnCallGrafana Cloud
#9. Splunk On-Call (VictorOps)observability
#10. BigPandaAIOps
#11. xMattersautomation
#12. Better Stackstatus + IR
#13. MoogsoftAIOps
#14. OnPagesecure paging
#15. PagerTreelightweight
#16. Spike.shsimple IR
#17. iLertEU-friendly
#18. ManageEngine ServiceDesk PlusITSM
#19. FreshserviceITSM
#20. Jira Service ManagementAtlassian
Key Features to Look For in 2025 Incident Management Software
Not all incident management tools are created equal. Some act as little more than alert routers, while others function as complete incident management solutions that help teams cut downtime, reduce alert fatigue, and scale incident response. If you’re evaluating incident response software in 2025, here are the features that matter most:
1. Noise reduction and smart alert routing
The best incident management software filters the signal from the noise. SREs report thousands of alerts every week, but only a small percentage require action. Look for AI incident management software that uses correlation, deduplication, and prioritization to keep engineers focused on the real issues.
2. On-call management that works for humans
Fair on-call rotations, clear escalation paths, and “follow the sun” coverage are critical. Good incident management tools make scheduling simple, swaps painless, and escalation rules transparent.
3. Native ChatOps integration
Incidents don’t happen in dashboards, they happen in Slack or Microsoft Teams. Modern incident management solutions plug directly into chat, creating war rooms, assigning roles, and logging timelines automatically.
4. Stakeholder communication
The right incident management software doesn’t just alert engineers. It also updates customers and executives with automated status pages and templated comms. That way, SREs fix incidents instead of writing “we’re working on it” emails.
5. AI-powered root cause context
In 2025, incident response software should do more than page people. AI-driven incident management software surfaces related logs, metrics, and dependencies, and even suggests possible root causes. The faster you get context, the lower your MTTR.
6. Postmortems that reduce repeat incidents
Every incident should end with learning. The best incident management tools include structured postmortem templates, action item tracking, and integrations into Jira or GitHub. That way, fixes actually happen, and repeat incidents go down over time.
7. Integrations with tools you already use
Your incident management solution should fit seamlessly into your stack including observability platforms (Datadog, Grafana, Prometheus), ticketing systems (Jira, ServiceNow), and deployment tools. Without that, you’re stuck copying data between silos.
8. Scalability and fair pricing
Finally, look for incident management software that grows with your team. Pricing should be transparent, ideally per user rather than per incident, so you can plan for scale without surprise bills.
Incident Management Software FAQs
Answers to the most searched questions about incident management software, tools, pricing, and integrations.
01What is incident management software?
02Which is the best incident management software in 2025?
03What are must-have features in incident management tools?
04What’s the difference between incident management tools and incident response software?
05Is there free incident management software?
06How does AI improve incident management?
07What metrics should teams track—SLA, SLO, MTTR?
08What’s the difference between ITSM tools and incident management software?
09Which incident management tools integrate with Slack, Jira, and GitHub?
10How do I choose the best tool for my team?
11Do incident management platforms support compliance and reporting?
12Can incident management software reduce downtime costs?

Rohan Taneja
Writing words that make tech less confusing.
